在 LLM 應用蓬勃發展的時代,將大型語言模型(LLM)推向生產環境往往只是旅程的開始,而不是結束。想像一下,一個聊天機器人應用在內部測試中表現完美,但上線後卻頻頻產生幻覺(hallucinations), 即輸出虛假事實導致用戶對產品的信任度降低,亦或是因延遲問題造成高額成本浪費。這些「看不見的失敗」在傳統 APM 系統中或許能透過基本監控捕捉,但 LLM 的概率性輸出、動態輸入和複雜上下文,讓它們像黑箱一樣難以預測。根據 Gartner 的預測,至少 30% 的 GenAI 專案將在 2025 年因這些風險而被中止,而超過 80% 的 AI 項目無法持續產生價值。
LLM 可觀測性正是解決方案的核心。它不僅是監控性能指標,更是系統性地收集和分析 LLM 的輸入、輸出、行為和用戶互動數據,以實時診斷問題、確保安全性並優化效能。這不僅能防範偏見傳播、模型漂移和安全漏洞(如提示注入),還能幫助開發者建構更安全、更智慧、更可擴展的 AI 系統。
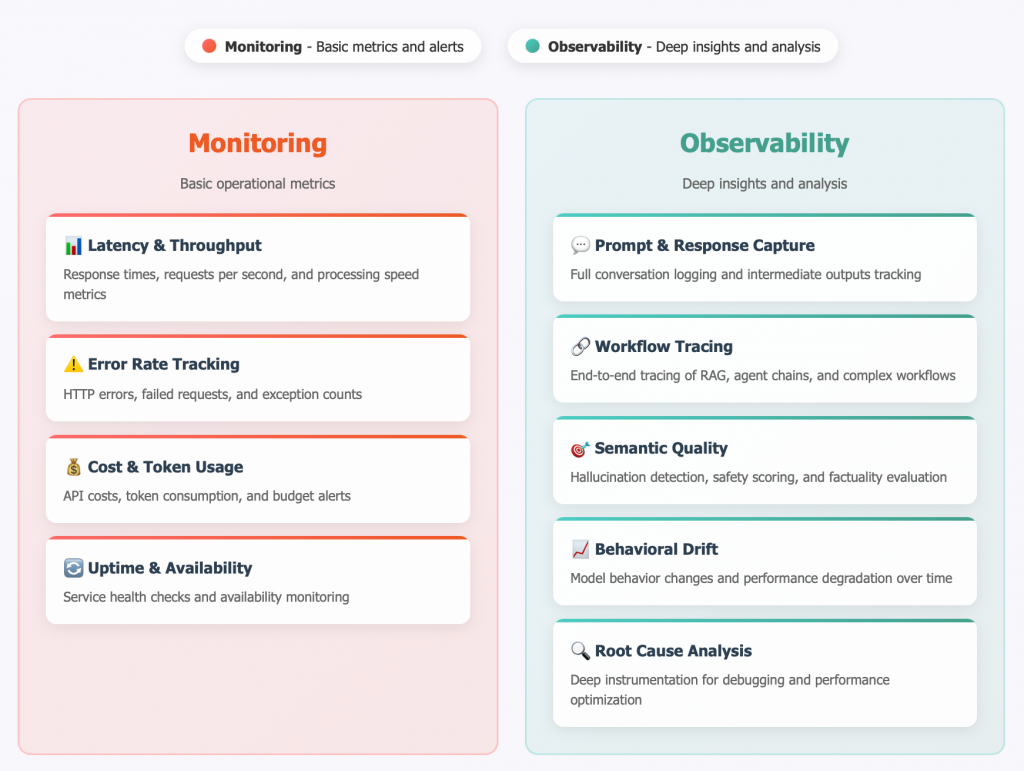
要理解 LLM 可觀測性,首先需區分它與傳統監控的差異。監控聚焦於症狀,如延遲、吞吐量、錯誤率、成本和 token 使用率。而這些都是表面指標,只是讓儀表板看起來「健康」,他沒辦法直接表現出系統的輸出「品質」是良好,因為在過去只要使用者收到回覆就代表成功。但 LLM 可觀測性更深入,它擴展到 MELT 框架(Metrics、Events、Logs、Traces),捕捉提示(prompts)、回應、嵌入(embeddings)和工作流程追蹤(如 RAG 或代理鏈),並評估語義品質,包括幻覺率、安全性、事實性和一致性。這讓開發者不僅看到「什麼出了錯」,還能診斷「為什麼出錯」。
LLM 面臨的特有挑戰源於其概率性和非確定性輸出:
更進一步的與過去人們熟悉的機器學習監控相比,LLM 可觀測性更專注於開放式輸出和語義評估。例如,ML 使用數值指標如 F1 分數或 ROC-AUC,而 LLM 依賴 LLM-as-a-judge、評分和人類反饋。
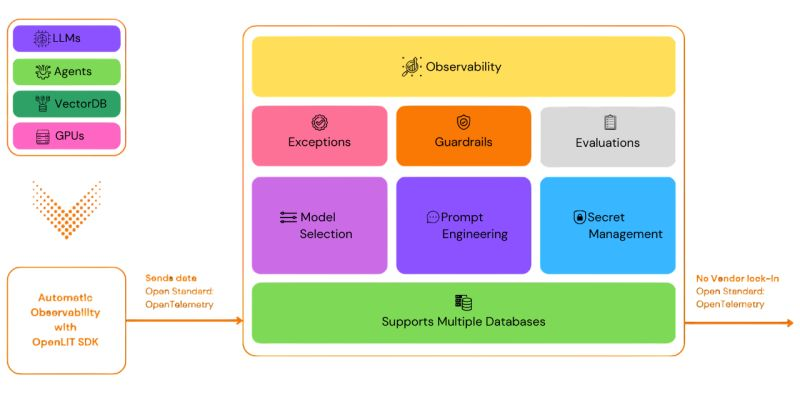
以開源解決方案 OpenLit 與 Langfuse 的功能架構為例,一個有效的 LLM 可觀測性平台,照字面上來說應該具備涵蓋我們,以應對上述挑戰。基於實務框架,它需要涵蓋四個支柱:遙測(telemetry)、自動評估(evaluation)、人類在回路中(HITL)品質保證,以及安全與合規的護欄(guardrail)。
遙測是可觀測性的最重要的基礎:要完整捕捉提示、回應、嵌入、token 用量、延遲與錯誤率。實務上,它同時支援診斷與合規追蹤;例如在 RAG 中,我們需要量到檢索是否找對內容與模型是否引用了正確脈絡。最佳做法是把資料即時串流到同一觀測面板,避免資料孤島,讓開發者能在分鐘級定位瓶頸(如 p95 延遲抬升或重試暴增)。
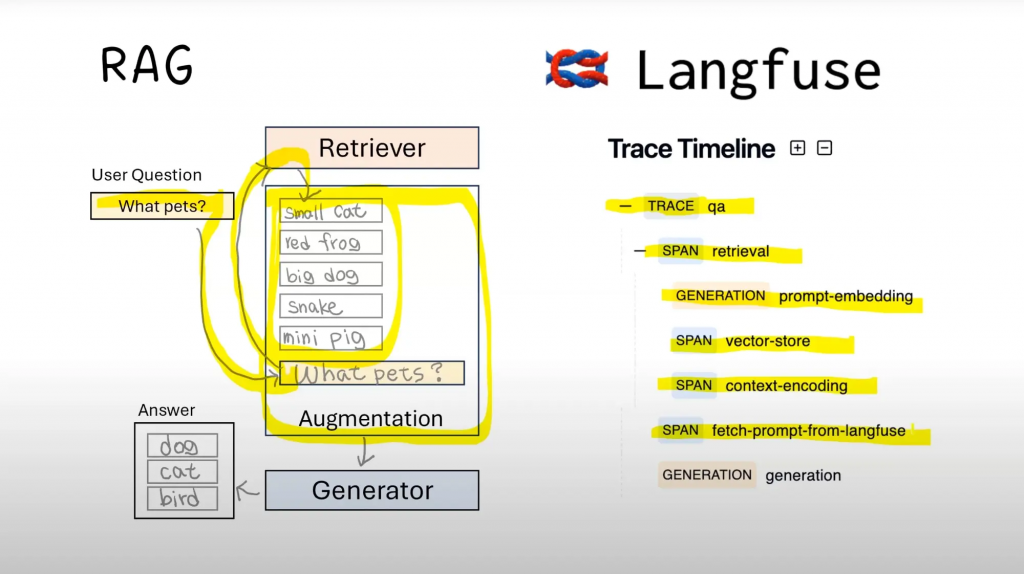
以一個 RAG 工具呼叫為例:流程通常是 embedding → retrieval →(必要時)rerank/encoding → context 組裝 → 與 prompt 一起送入 LLM。任何一步的偏差都會把最終答案帶離題(例如嵌入老化導致召回下降、context 組裝截斷了關鍵段落)。因此,用規範化的事件格式與可視化記錄每一步,至少包含:請求 trace/span、模型與索引版本、k 與分數、p95 延遲、token 成本、錯誤碼,以及簡單的品質訊號(如 Recall@k、Context Hit Rate)。做到這些,才能真正看清複雜 LLM/Agent 在實際環境中的核心運作細節。
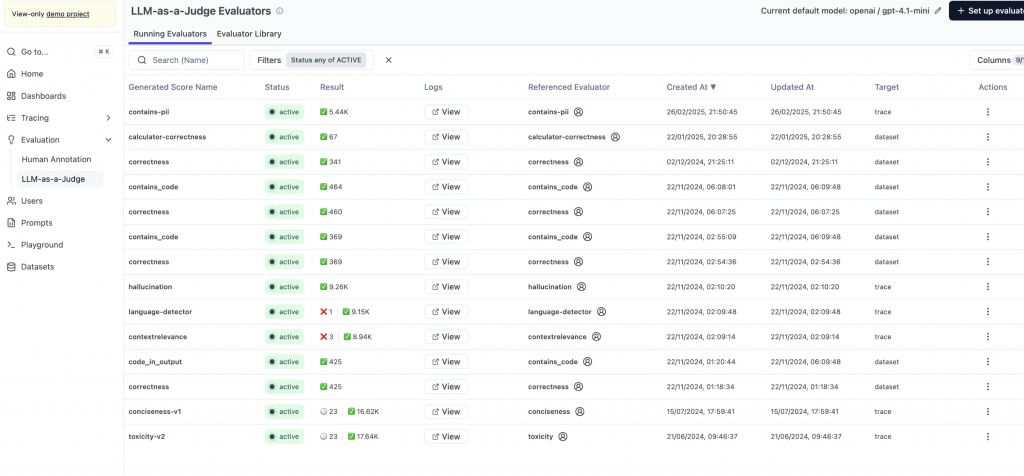
使用 LLM-as-a-judge 或回歸測試套件,評估輸出的事實正確性、相關性、一致性和安全性。關鍵指標包括 BLEU/ROUGE 分數(文本相似度)、幻覺率和偏見檢測。價值見解:這能將手動審核從 100% 降至 10%,透過活躍學習(active learning)優先標註高風險樣本,提高效率。
LLM-as-a-judge 可視為不知疲倦的 QA:依你定義的評分規則,持續、批量檢查輸出是否達標。在現實世界的業務場景中,任何可能影響 Agent 應用輸出品質的變更(prompt、檢索策略、模型版本),都應在上線前的 CI 階段跑回歸集,設定明確閾值與阻擋條件(例如:幻覺率不升、ROUGE 不降、敏感詞零容忍);同時保留離線資料樣本,避免「改 A 壞 B」或越改越差。這樣能把品質把關變成可重複、可量化的工程流程。
再強的自動化也取代不了人類對領域脈絡的判斷。就像單元測試只能覆蓋「已知情境」,在真實商業邏輯中(需求頻繁變更、多團隊並行、用戶行為遷移),測試集的品質終究需要人來維護——特別是挑選「最有價值的黃金資料集」與界定灰區標準。
因此,平台需內建 標註佇列 與 即時協作:可指派審核、並行評註、留言釐清標準,形成可追溯的決策歷程,讓專家聚焦在邊緣案例與高風險樣本:
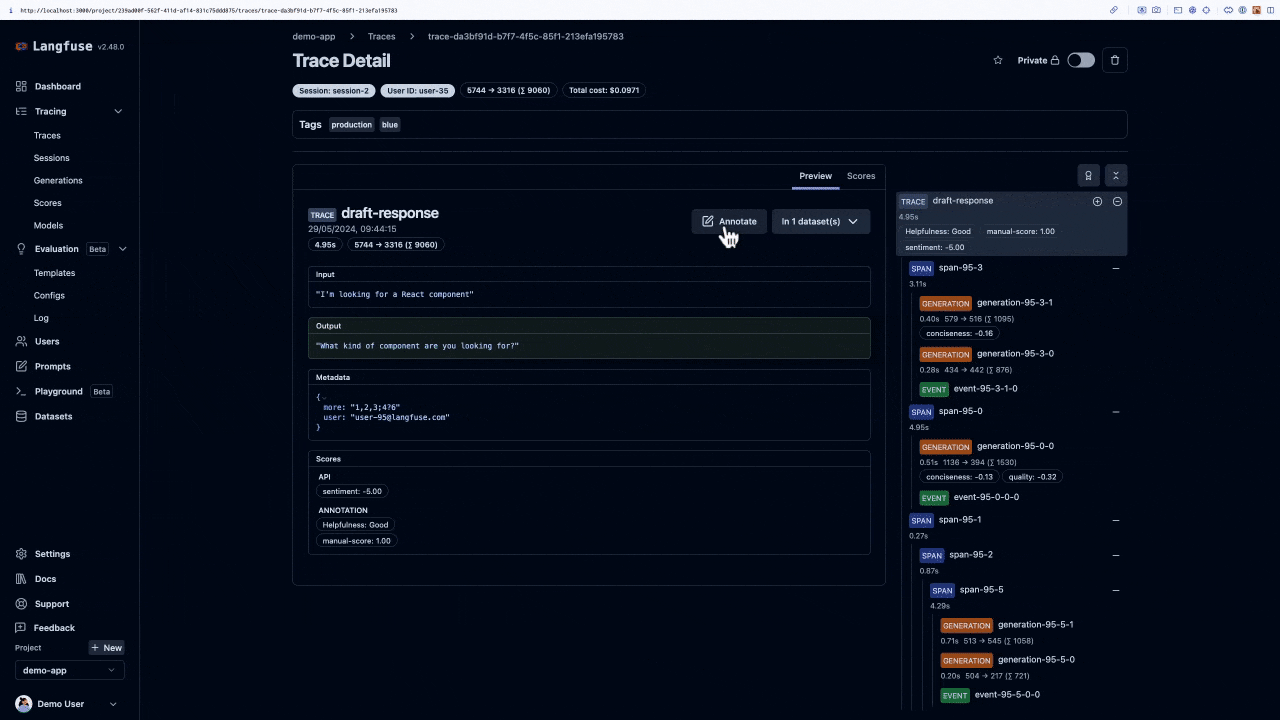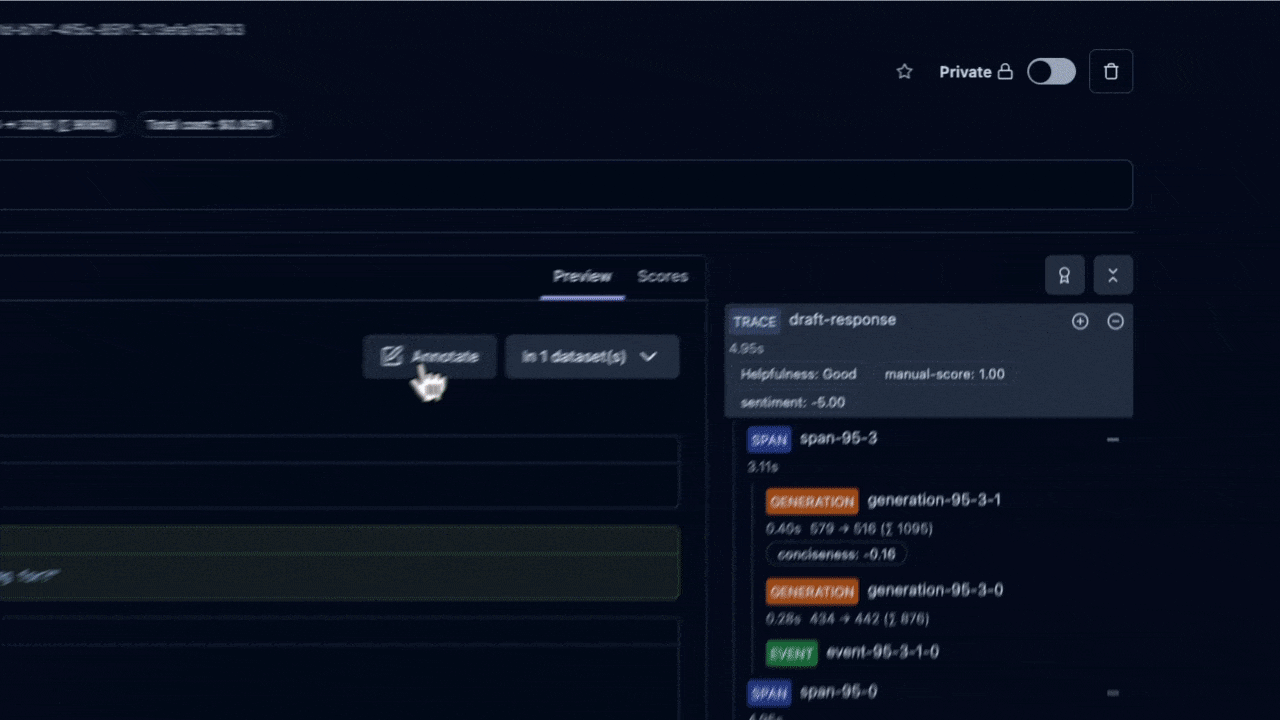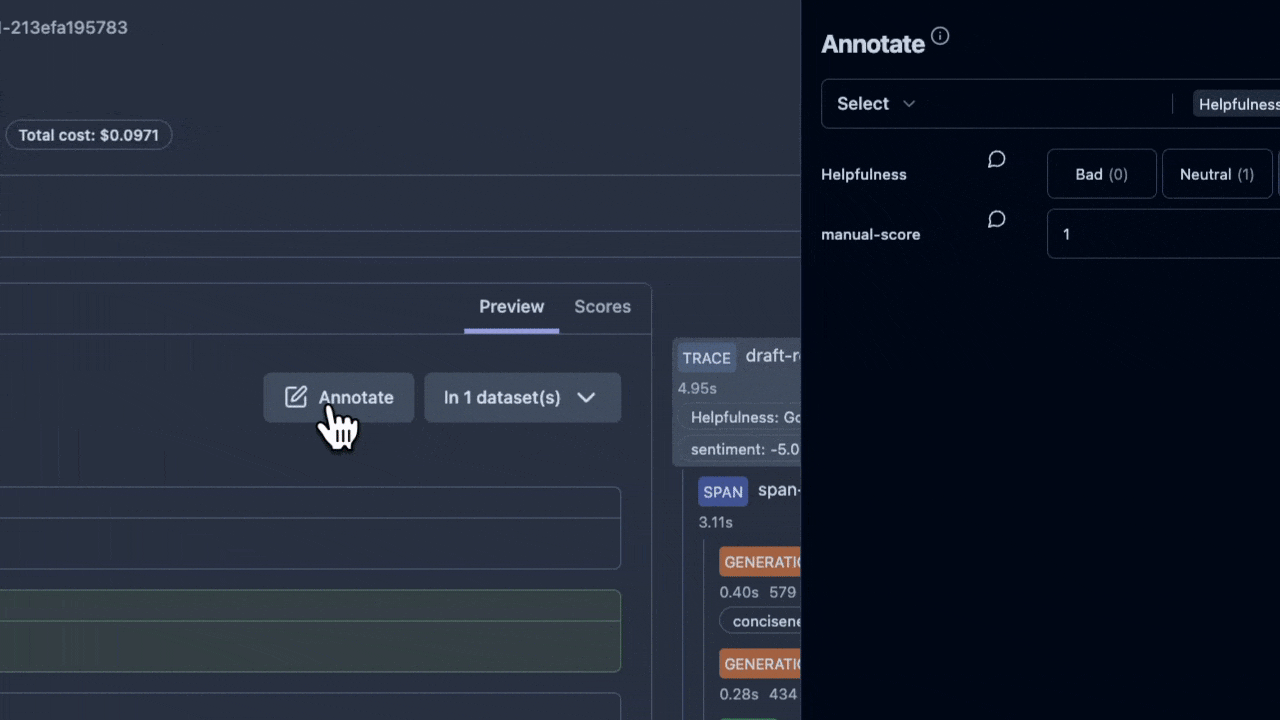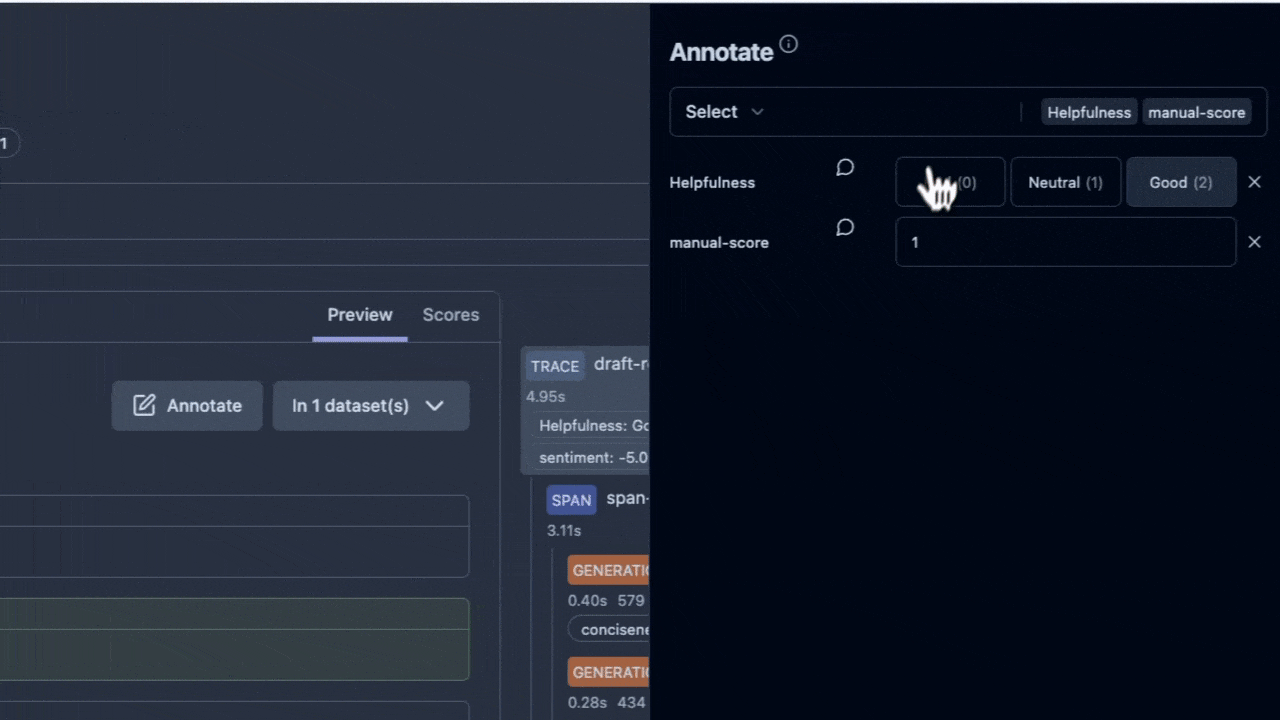
整合 PII 檢測、提示過濾、審計日誌,確保符合 GDPR 等法規;同時保留未來空間,例如依風險分數動態調整提示或策略回退。
常見安全庫可降低基於 LLM 的應用風險,包括:
LLM Guard、Prompt Armor、NeMo Guardrails、Microsoft Azure AI Content Safety、Lakera。
它們通常透過以下方式落地安全措施:
在此之上,可觀測性平台要做的是把安全評分與風險事件串進決策與追蹤:
需要注意的是,部分安全檢查必須在模型前阻塞或在回應前終止,很容易成為整體延遲瓶頸。可觀測性應拆分量測這些檢查的延遲(例如 p95)、超時與命中率,讓團隊判斷哪些檢查值得等待、哪些可異步處理/快取/降級,在不犧牲安全的前提下控制體驗與成本。
https://signoz.io/blog/llm-observability/
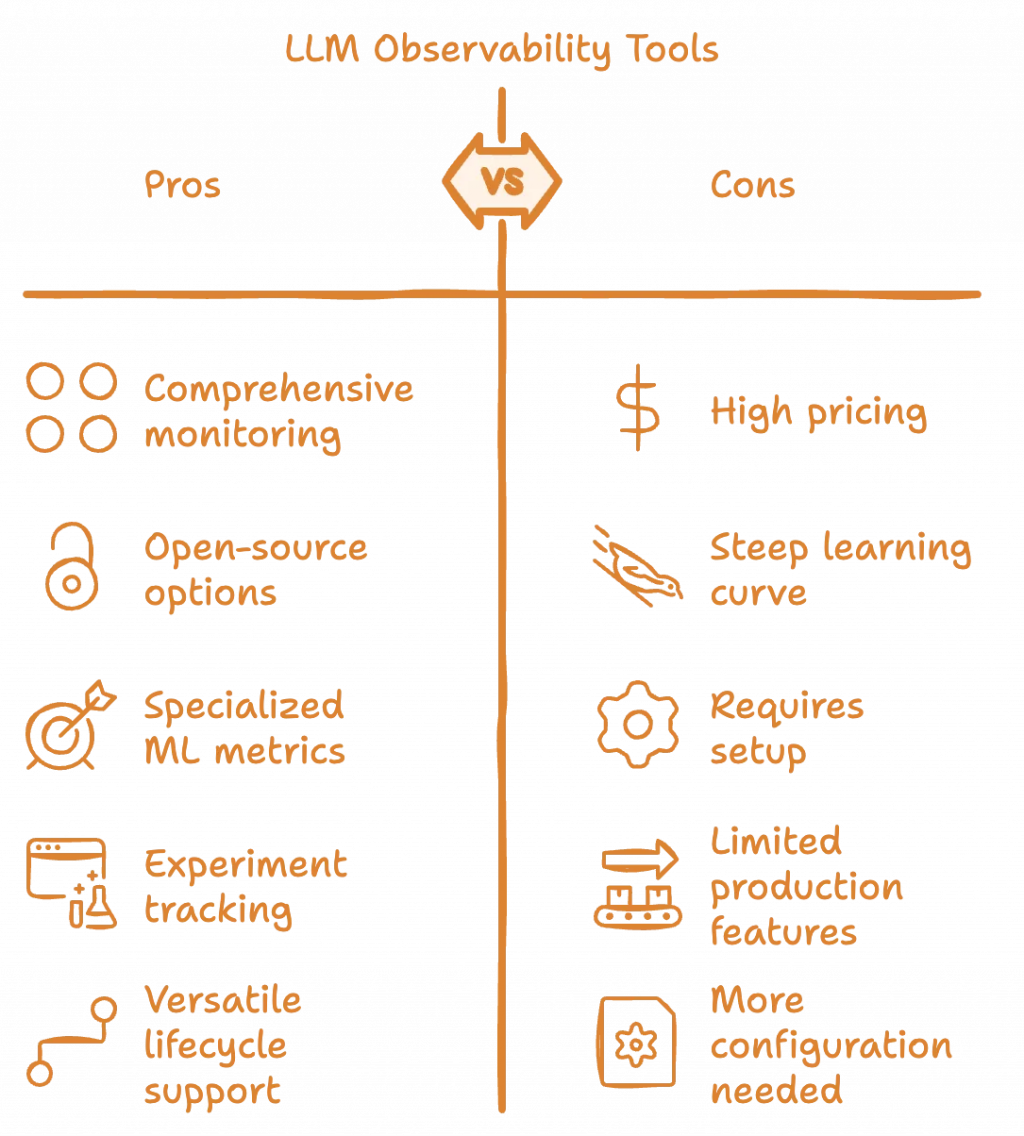
LLM 可觀測性平台能提供從效能到語義層的全方位監控與實驗追蹤,並內建針對 LLM 的專屬指標(如幻覺、漂移),可支援從開發到上線的完整生命週期;但同時伴隨成本高、上手難、需要整合與配置等落地阻力,且部分方案在離傳統的成熟監控工具相比上仍然有限。
什麼時候值得
可能的代價
選擇建議
| 方案 | 部署/授權 | 強項 | 可能限制 | 最適用情境 |
|---|---|---|---|---|
| LangSmith | SaaS + 自託管 | 端到端 Tracing / Dataset / Evaluation / 實驗 與 LangChain/LangGraph 深度整合。 | 商用授權為主;非 LangChain/Graph 流程可接 OTel,但要花點時間貼合既有框架語意。 | 已採用 LangChain/LangGraph,且不打算自建可觀測性平台。 |
| Langfuse | 開源 + SaaS / 自託管 | 功能完整(Traces / Evals / Prompt 管理 / Datasets / Metrics),v3 架構支援 Postgres + ClickHouse(+Redis/S3),可撐到大量事件與資料列級別。 | 架構較厚重(自託管需多個基礎設施元件與維運)。 | 重視資料主權與可擴展性、要做嚴謹的 Prompt 治理與成本/品質量化的團隊。 |
| Arize Phoenix | 開源 + SaaS | 以 實驗/評估/故障排除 為核心;OTel/開放規範友好、易與既有觀測平台打通;提供 Datasets / Experiments / Playground。 | 預設輕量,要跑到組織級長期留存/多租戶,需要規劃資料庫、保留期與批處理;雲端免費空間有容量/保留期界線。 | 想用 OTel 迅速把 LLM 可觀測性接入現有堆疊,並做完整評估/實驗的團隊。 |
| OpenLIT | 開源 | 以 OTel 原生儀表化 為核心,覆蓋主流框架與向量庫;支援 成本/延遲/抖動 觀測、GPU/向量庫 監控與基本評估/對比。 | 偏 SDK/儀表化優先,平台化功能(資料集、評估工作流治理)相對輕;需要自行接上你現有的可觀測性後端。 | 已有自家觀測平台(如 Datadog/Grafana/Tempo 等)且想用 OTel 整合 LLM 可觀測性需求。 |
| Helicone | 開源+SaaS;同時提供 AI Gateway 服務。 | 在 Gateway 層 能完整蒐集 成本/延遲/配額 等指標,也有 實驗/Evals/Tracing(可搭配 Logger/OTel);常與其他平台併用。 | 以 Gateway/成本分析見長;評估/治理 相對 LangSmith/Langfuse/Phoenix 較輕,複雜實驗/資料集管理多半需搭其他平台。 | 先把 成本與延遲 控好,再逐步補齊品質與治理面的團隊;或希望用 一鍵代理 快速接多家模型供應商者。 |
從上面的表格中,可以明顯看出市場主流的 LLM 可觀測性正快速朝 OpenTelemetry 標準化收斂;多數平台同時提供雲端託管與自託管選項,並把 Tracing→Datasets→Evaluations 串成閉環,以支援「回放→改 Prompt/路由→再驗證」的節奏:
LLM 可觀測性是建構可靠 AI Agent 應用的基石,它不僅監控系統,還賦能開發者預測和預防問題,實現更安全的輸出、更智慧的優化和更可擴展的部署。未來趨勢包括多模態整合(處理影像+文字)、自動化修復(如 AI 驅動提示優化)和開源生態崛起,預計到 2025 年,持續評估將成為標準,幫助企業避開 Gartner 預測的專案中止潮。 下一篇文章中,我們將深入平台比較和實務案例,從小規模實施開始,我們的 LLM 應用將更穩健。